生まれたばかりの息子をもっと理解したいので育児記録アプリの「ぴよログ」の記録を解析する(ファイル読み込み編)
Twitterで報告しましたが、11月に息子が生まれました。そして、ちょうど今週、妻が里帰りから帰ってきました。なので、ついに私も本格的に育児を開始したのですが、我が息子ながら何がどうなっているのか何もわからん!ということで息子の理解度を高めるために使っていた育児記録アプリであるぴよログの記録データを解析してみようと思い立ちました。
今回はその第一弾としてぴよログの記録のデータ読み込みについてとそれを使った簡単なデータ解析についての記事になります。
ちなみに今回のぴよログのファイル読み込みライブラリはここに公開しています。
https://github.com/shu65/piyolog_reader
目次
育児記録アプリのぴよログとは?
ぴよログとは育児中のミルクをあげた時間や睡眠時間、うんちやおしっこの時間などいろいろなことを記録して、共有できるスマホアプリです。詳しくは以下のサイトを見てください。
妻が出産前に調べて「これがよさそう!」ということで生まれてすぐから使い始めています。ぴよログに記録をとることで、いつミルクをあげたのかなどがスマホを見ればわかるので、妻と育児を交代するタイミングでも口頭で「〇時にミルクをあげたから次は〇時にお願い」みたいなやり取りが発生しないためスムーズに交代できるのですごく便利です。そんなぴよログですが、記録を出力することができます。
出力されるデータはCSVなどの構造化データではなく、ある程度規則的な形式のテキストで出力されます。おそらくEvernoteなど別のノート系のアプリに張り付けられるようにするための機能なのではないかと思っています。本来の用途とは少し違う気もしますが、テキストで出力されているので頑張ってパースすればデータ解析までもっていけそうだなと思いました。実際、調べてみるとQiitaで以下のようにぴよログの記録を読み込む記事を書いている方がすでにいます。
https://qiita.com/yakipudding/items/11223f12a843e4399300
簡単な読み込み関数はこの記事でも紹介されています。ただ、もう少し自分がデータ解析しやすい形で出力したいなということで今回は別の読み込み関数を書きました。
ぴよログのファイルを出力してデータ解析する
ここからはぴよログの記録をファイル出力して簡単なデータ解析するまでの流れを順に説明します。
ぴよログの記録のファイル出力
まず、ぴよログの記録の出力方法について説明します。
やり方としては「メニュー」→「記録の出力」→「データのエクスポート」で1日もしくは1か月分のデータを別のアプリに共有することができます。
後ほどGoogle Colabで解析しやすいようにこの記事では1か月分のデータをGoogle Driveにあげたという仮定で説明していきます。
ぴよログのデータ読み込みの準備
さて実際のデータ読み込みの前の準備です。まずは私の書いたぴよログの記録の読み込みライブラリのコードのインストールです。2022/12/30現在は以下のようにしてインストールするようになっています
pip install git+https://github.com/shu65/piyolog_reader.gitちなみに2022/12/30現在、Google Colabで解析する場合は pandas のパッケージが古く、timezoneの扱い周りでエラーが出てしまっているようなので以下のように最新版にあげておいたほうが良いと思います。
pip install -U pandas次にGoogle ColabでGoogle Driveにアクセスできるようにマウントします。コードとしては以下の通りです。
from google.colab import drive
drive.mount("/gdrive")このコードを実行するとGoogle ColabからGoogle Driveにアクセスするための認証がでてきますので、許可します。
事前にGoogle Driveの notes/piyolog というディレクトリにぴよログのデータを入れておいたとすると、以下のようにls コマンドで /gdrive/MyDrive/notes/piyolog/ にアクセスするとぴよログの記録データがあります。
!ls /gdrive/MyDrive/notes/piyolog/このls の出力はこのような形になります。
【ぴよログ】2022年11月.txt 【ぴよログ】2022年12月.txtこれで前準備としては終わりです。
ぴよログの記録の読み込み
さて、ここから本番のぴよログの記録の読み込みを行っていきます。今回はディレクトリに入っている全記録を読み込むようにします。コードとしては以下の通りです。
import glob
import piyolog_reader
log_pathes = glob.glob("/gdrive/MyDrive/notes/piyolog/*")
dfs = piyolog_reader.read_texts(log_pathes)dfs の中に記録の情報をpandasのDataFrame を使って種類ごとに分けて格納しています。このように種類ごとに分けた理由としてはデータベースのスキーマ設計の正規化を意識してやりました。このあたりの仕様はあとで解析して使いにくかったら変える可能性があるので細かくは説明しませんが、記録の日時と記録の種類は dfs["event"] というDataFrame にいれています。printするとこのようになります。
timestamp event
index
0 2022-12-01 01:00:00+09:00 起きる
1 2022-12-01 01:05:00+09:00 おしっこ
2 2022-12-01 01:05:00+09:00 うんち
3 2022-12-01 01:10:00+09:00 搾母乳
4 2022-12-01 01:15:00+09:00 ミルク
... ... ...
1990 2022-11-30 21:35:00+09:00 起きる
1991 2022-11-30 21:40:00+09:00 母乳
1992 2022-11-30 21:40:00+09:00 おしっこ
1993 2022-11-30 21:55:00+09:00 ミルク
1994 2022-11-30 22:30:00+09:00 寝る
[1995 rows x 2 columns]indexに記録ごとに一意の番号をふってあるので、他の記録をまとめた別のDataFrameとマージすると日時とその記録の情報のデータフレームを簡単に得ることができます。例えば体重の DataFrame は dfs["weight"] にまとまっているので、それとマージすると以下のようになります。
import pandas as pd
weight_df = pd.merge(dfs["event"], dfs["weight"], left_index=True, right_index=True)
print(weight_df)出力は以下の通りです。
timestamp event weight
index
41 2022-12-01 17:40:00+09:00 体重 3.00
329 2022-12-07 09:40:00+09:00 体重 3.25
757 2022-12-16 09:10:00+09:00 体重 3.69
1347 2022-11-15 13:35:00+09:00 体重 2.76
1725 2022-11-25 16:10:00+09:00 体重 2.79これでぴよログのデータの読み込みをすることができました。
ぴよログのデータを使った簡単なデータ解析
さて、ぴよログのデータを使って簡単なデータの解析も行う例も示しておこうと思います。今回は以前に息子が順調に育っているのか心配になって体重の変化量がどの程度なのか?を調べたので似たようなことをぴよログの記録とPythonを使って簡単にやってみる例を示します。
まず、生まれた日と体重測定日の差の日数を以下のように先ほどのweight_dfに追加します。
birthday_str = '2022-11-15T00:00'
birthday = pd.to_datetime(birthday_str)
birthday = birthday.tz_localize('Asia/Tokyo')
weight_df["day"] = (weight_df["timestamp"] - birthday).dt.days
print(weight_df)出力としては以下の通りです。
timestamp event weight day
index
41 2022-12-01 17:40:00+09:00 体重 3.00 16
329 2022-12-07 09:40:00+09:00 体重 3.25 22
757 2022-12-16 09:10:00+09:00 体重 3.69 31
1347 2022-11-15 13:35:00+09:00 体重 2.76 0
1725 2022-11-25 16:10:00+09:00 体重 2.79 10あとはscikit-learn で線形モデルにフィッティングさせて day の重みを見ると大体、一日の体重変化量が分かります。コードとしては以下の通り。
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
model = LinearRegression(positive=True)
model.fit(X=weight_df[["day"]].values, y=weight_df["weight"])
y_pred_train = model.predict(X=weight_df[["day"]].values)
mae_train = mean_absolute_error(y_pred=y_pred_train, y_true=weight_df["weight"])
rmse_train = np.sqrt(mean_squared_error(y_pred=y_pred_train, y_true=weight_df["weight"]))
print("coef", model.coef_, "intercept", model.intercept_, "mae_train", mae_train, "rmse_train", rmse_train)出力としては以下の通り。
coef [0.03083936] intercept 2.610738060781476 mae_train 0.10900144717800293 rmse_train 0.11535210050611226coef の一つ目の要素がday に対する重みで約0.03となっています。単位はkgなので、大体30gくらい1日に増えていることがわかります。体重が増加してなかったらヤバイそうなので、その点は大丈夫そうということがわかりました。ついでに0日から現在データとしてあるところから10日ほど未来まで体重を予測してみた結果と実際の測定値を図を以下に示します。
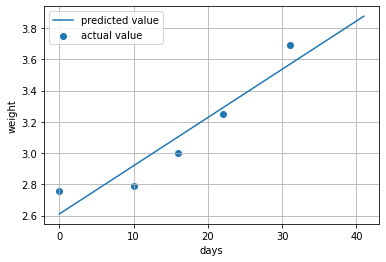
図の描画のコードは以下の通りです。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
plt.scatter(weight_df["day"].values, weight_df["weight"].values, label="actual value")
x = np.linspace(0, weight_df["day"].max() + 10.0, 100).reshape((-1, 1))
weight_pred = model.predict(x)
plt.plot(x[:, 0], weight_pred, label="predicted value")
plt.xlabel("days")
plt.ylabel("wegiht")
plt.legend()
plt.grid()おわりに
今回は生まれたばかりの息子をもっと理解したいという思いから育児記録アプリのぴよログの記録データを読み込んで簡単な解析をした結果を紹介しました。まだまだ取り組みとしては始めたばかりなので、これからデータをいろいろ見てみようと思います。もし面白そうなネタがあったらまた記事にしようと思います。
